

A Lehmer Sieve made of LEGO. The pins represent quadratic residues.
In his excellent and excellently-named expository piece A Tale of Two Sieves, Carl Pomerance tells the history of two factoring algorithms, the quadratic and number field sieves. This story begins with a factorization technique called factorization via congruence of squares, which attempts to factor 

If such a congruence is known, then 




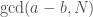
This is a great start but it doesn’t tell us how to produce these congruences of squares in the first place. Kraitchik’s idea back in the 1920s was to find them by multiplying together non-square quadratic residues with “simple” prime factorizations. We illustrate this by (stealing Pomerance’s) example:
Example 1. Let’s factor the integer 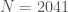

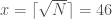

These are quadratic residues (by construction), but none of these are squares, so Fermat would keep on looking. But what Kraitchik observes is that some of these outputs factor entirely into small primes:



By looking at prime factorizations, it’s not hard to find a combination of these outputs that gives a perfect square. For example, 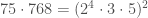
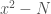

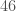


Since 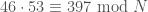



we get a non-trivial factor of 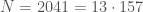
The purpose of this article isn’t to rehash A Tale of Two Sieves. Rather, I’d like to explore the bits and pieces that make Pomerance’s example work so nicely. For contrast, here’s a bad example:
Example 2. Let’s factor 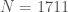
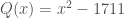



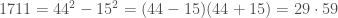
But that’s not the only way things can go wrong. Here’s a failure of a different sort:
Example 3. Let’s factor 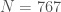








Around now, the numbers start getting large. For the sake of efficiency, we might stop factoring 
This spirals. Searching even two million 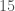
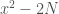
Given all this, just how special is Pomerance’s example
. I’ll be the first to admit that the bound
. Moreover, it seems natural to look at semiprimes because one of the main “industrial applications” of factoring is the breaking of RSA keys.
- The example shouldn’t devolve into Fermat’s Method. Factorization based on congruences of squares is often pitched as an improvement to Fermat’s Method. It’s therefore silly to work through an example that reverts back to this simpler technique. (See Example 2.)
- The example shouldn’t require an overly large smoothness bound. Here, large is a bit subjective. Pomerance notes that the optimal smoothness bound for large
Being charitable, we’ll call an example “bad” if the values of
-smooth numbers is found, where
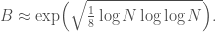
These conditions create a fairly sparse of potential 




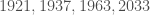
Example 4. Let’s factor 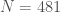
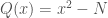
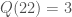



gives a non-trivial factor of
I suppose the funny thing about this example is that it has succeeded a bit too well. To better highlight Kraitchik’s Method, let’s also restrict to the cases where first two outputs of 
Example 5. Let’s factor 


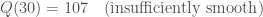

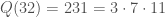

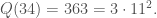
Then 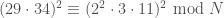

This is the first of our examples that feels like a solid introduction to Kraitchik’s Method. We have some smooth outputs, some not-so-smooth outputs, and enough terms to get you thinking about how you might find a square-producing subset in a more general case.
Pomerance does a few other computations with 
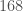


If one wants to arrange for the first square-producing subset to use more than two terms, the list of admissible 


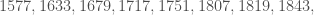


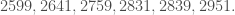
Example 6. Let’s factor 
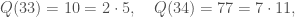

In this case, the first congruence of squares we find is not useful: it reads 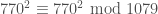
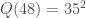
Example 7. Let’s factor 


Then 

In the previous example, we defined “sufficiently smooth” as 

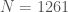
Example 8. Let’s factor

Then 
As a parting gift, here’s a full list of 
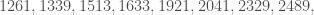



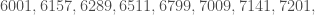


This list contains Pomerance’s example 
