

Substitution ciphertext from Edgar Allan Poe’s “The Gold Bug.”
A (monoalphabetic) substitution cipher is an encryption scheme in which characters in the plaintext and ciphertext correspond in a one-to-one fashion. Substitution ciphers include, as special cases, well-known and classic ciphers like ATBASH and the Caesar shift. More generally, the underlying permutation (known as the key) will have no special structure: it will be a random permutation drawn from the space of 26! potential keys. The size of this keyspace is fairly large, even by modern-ish (ca. 1990s) standards, but a large keyspace does not in itself guarantee security.
It was known as early as ~850 CE (in the work of al-Kindi) that frequency analysis could be used to crack substitution ciphers. Despite this, substitution ciphers (in various and increasingly-complex incarnations) saw continued use until the end of the late medieval period (ca. 1500 CE), when they were supplanted by more robust creations, like the Vigenère cipher.
In general, the number of characters required to carry out a brute-force keyspace attack on a cipher is called the unicity distance of the cipher. The substitution cipher on an English lowercase alphabet has a keyspace of size 
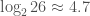
More realistically, about 50 characters are required to crack a substitution cipher, although this number increases if the text is unusual (for example, if the letter distribution is unusually flat or if the writing is otherwise constrained). The “e”-less phrase,

of 57 characters, is one such example. Given a “normal” string of text (such as an un-parsed lower-case character string from a random article on Wikipedia), 50 characters is a pretty good stretch goal for computer-assisted solves.
In what I’ve seen, there are two main algorithms employed for the automated solution of substitution ciphers. The first is combinatorial in nature: word lengths are guessed, then letters are assigned to pattern-match words in a large dictionary. (This technique is particularly efficient in the variant problem where spacing is preserved. See one implementation here.) The second algorithm is more probabilistic: a statistical model is imposed on the k-grams of the text, and letters are swapped so as to maximize the “fitness” of the decrypted text. (See one example here.)
There is plenty of variation in each approach. In the second, for example, one can select letter swaps based on hill-climbing or genetic algorithms. In my experience, genetic algorithms are more useful because the fitness landscape in this problem is rife with local maxima.
I’ve linked a Mathematica file (and some auxiliary data files) at the end of this post which implements a genetic algorithm to solve un-parsed substitution ciphers. The algorithm makes an initial guess at the key based on letter frequencies (i.e. 1-grams), then mutates and appraises candidate keys based on progressively longer k-grams. It can decrypt most 70-character strings in fewer than 100 generations. For shorter strings, the main challenge seems to be in the choice of fitness functions: it’s hard to produce fitness functions for which the desired plaintext is a global (or even local) maximum.
Click here to access a Dropbox folder containing the aforementioned files.
