At this moment, the fastest general-purpose factoring algorithm for extremely large integers is the general number field sieve (GNFS), invented by Pomerance in 1989 (as a generalization of Pollard’s special number field sieve from 1988). The GNFS has a heuristic runtime which is sub-exponential in the size (in bits) of the input. In particular, the GNFS is much, much faster than trial division at finding factors of large integers. (The worst-case runtime for trial division is exponential in the bit size.)
This is not to say that the GNFS is the exclusive tool used in finding factorizations today. The algorithmic overhead required to implement the GNFS is immense, so much so that it only starts to eclipse other algorithms when used to factor integers of 400 bits or more. (This translates to around 120 decimal digits.) For smaller inputs, different methods will out-perform the GNFS:
For one concrete example, the computer algebra system Mathematica uses a combination of trial division, Pollard’s 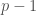 Method, Pollard’s
Method, Pollard’s  Method, ECM, and the quadratic sieve to implement its built-in function
Method, ECM, and the quadratic sieve to implement its built-in function FactorInteger[]. Note that Mathematica doesn’t even bother to implement the GNFS. In practice, the GNFS is only used in dedicated, distributed computing projects.
The quadratic sieve was the major inspiration for the GNFS and operates by searching for congruences of the form  . Pollard’s Method is a sort of Monte Carlo method, which obtains factorizations from cycles in the iterates of a pseudo-random map.
. Pollard’s Method is a sort of Monte Carlo method, which obtains factorizations from cycles in the iterates of a pseudo-random map.
The other three algorithms Mathematica uses (trial division, Pollard’s Method, and the elliptic curve method) are all examples of algebraic group law factorization algorithms. Broadly speaking, these algorithms perform computations in an algebraic group 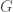 defined mod
defined mod  for which the group structure decomposes (via Chinese Remainder Theorem) into components corresponding to the unknown prime powers dividing . If we can find an element of which projects to the identity in at least one but not all of the components of (and can detect this!) we can factor .
for which the group structure decomposes (via Chinese Remainder Theorem) into components corresponding to the unknown prime powers dividing . If we can find an element of which projects to the identity in at least one but not all of the components of (and can detect this!) we can factor .
This note discusses some of the more successful algebraic group law factorization algorithms, which include trial division, Pollard’s Method, Williams’  Method, and the ECM. We start simple, and work our way up in complexity.
Method, and the ECM. We start simple, and work our way up in complexity.
— 1. TRIAL DIVISION —
To find a non-trivial factor of using trial division, we simply check if  for each
for each 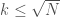 . Unless is prime (which is detectable in polynomial time), we’ll find a factor before
. Unless is prime (which is detectable in polynomial time), we’ll find a factor before 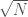 . Now, this isn’t what I’d call an algebraic group law factorization algorithm (AGLFA). To appreciate trial division as an AGLFA, we need to re-interpret some of our steps.
. Now, this isn’t what I’d call an algebraic group law factorization algorithm (AGLFA). To appreciate trial division as an AGLFA, we need to re-interpret some of our steps.
The underlying group in this case is the integers under addition. Viewed mod , we are looking at the additive group of  . For simplicity, let’s assume that has prime factorization
. For simplicity, let’s assume that has prime factorization  (as in the case of an RSA modulus). By the Chinese Remainder Theorem, we can write
(as in the case of an RSA modulus). By the Chinese Remainder Theorem, we can write
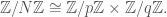
Recall, as a general goal, that we’re looking for an element  which equals the identity in exactly one of the components
which equals the identity in exactly one of the components 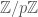 or
or  . One way to do this is to fix an element
. One way to do this is to fix an element 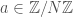 (at random, say) and look at the iterates of
(at random, say) and look at the iterates of  under the group action. If we can find an integer
under the group action. If we can find an integer 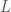 such that
such that

we will have found our partial identity. But how can we find without knowing  or
or  ? The idea is to search for in the sequence
? The idea is to search for in the sequence  . To identify a successful choice of , we need a way to determine if
. To identify a successful choice of , we need a way to determine if  is a partial identity. We can do this with a GCD computation, since
is a partial identity. We can do this with a GCD computation, since  if and only if
if and only if  is at least a partial identity. So, without further ado, here’s “trial division” as an AGLFA:
is at least a partial identity. So, without further ado, here’s “trial division” as an AGLFA:
- Choose a convenient value for .
- Starting at
 , replace with
, replace with  .
.
- Compute
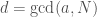 . If
. If  , return
, return 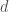 , a non-trivial factor of (and stop).
, a non-trivial factor of (and stop).
- Increment
 and return to Step 2.
and return to Step 2.
It’s easy to look at the algorithm above and see the ways in which it might be slower than traditional trial division. The trial division you’re used to takes  mod operations, in which is the smallest prime factor of . This takes time
mod operations, in which is the smallest prime factor of . This takes time  when and are both large. On the other hand, this algorithm involves modular multiplications of size and GCD computations. The runtime is therefore
when and are both large. On the other hand, this algorithm involves modular multiplications of size and GCD computations. The runtime is therefore 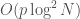 . The runtimes are thus comparable when is large, although the implicit constants certainly favor the traditional version.
. The runtimes are thus comparable when is large, although the implicit constants certainly favor the traditional version.
Remark — I’m aware just how silly this algorithm looks. The point here is just to create an analogy which we’ll develop in the next few sections. Some of the core ideas, like taking  or finding factors by computing GCD against , will be seen time and time again.
or finding factors by computing GCD against , will be seen time and time again.
— 2. POLLARD’S METHOD —
Pollard’s Method originates in a paper by Pollard from 1974 and is typically viewed as the archetypal AGLFA. In this case, the underlying group is  , the multiplicative group of units in . Since the Chinese Remainder Theorem is a ring homomorphism, we have
, the multiplicative group of units in . Since the Chinese Remainder Theorem is a ring homomorphism, we have  .
.
As in the additive case, we’ll search for a factor by taking a random and looking at the iterates of under the group action. If we can find an integer such that

we can recover as  . As before, we search for in the sequence . This leads to Pollard’s Method, which — when written in pseudo-code — looks almost exactly like our version of trial division:
. As before, we search for in the sequence . This leads to Pollard’s Method, which — when written in pseudo-code — looks almost exactly like our version of trial division:
- Choose a convenient value for .
- Starting at , replace with
 .
.
- Compute
 .
.
- If , return , a non-trivial factor of (and stop).
- If
 , return to Step 1 and choose a new .
, return to Step 1 and choose a new .
- Increment and return to Step 2.
Just how fast is Pollard’s Method? We note that 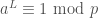 if and only if
if and only if  , and that
, and that 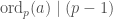 by Lagrange’s Theorem. In a worst-case (but not atypical) scenario, we’d have to increase until
by Lagrange’s Theorem. In a worst-case (but not atypical) scenario, we’d have to increase until  . As a rough heuristic, Pollard’s Method frequently terminates when
. As a rough heuristic, Pollard’s Method frequently terminates when  is the largest prime factor of .
is the largest prime factor of .
The runtime of Pollard’s algorithm depends dramatically on the shape of the hidden factors and . For example, Pollard’s algorithm factors

in just twelve iterations, while the seemingly-related

takes over a million iterations to complete. When Pollard’s method is at it’s worst — for example when and are both safe primes — the algorithm is no faster than trial division. For this reason, Pollard’s Method is typically classified as a special-purpose factoring algorithm; it won’t be efficient for most inputs, but there are cases when it is the only tractable approach. This is the role it plays in Mathematica.
The runtime for Method is typically  , in which
, in which  is the largest prime factor of (or
is the largest prime factor of (or  , if is found first). This can be contrasted with our algorithm based on trial division, which ran in time , in which is the largest prime factor of (i.e.
, if is found first). This can be contrasted with our algorithm based on trial division, which ran in time , in which is the largest prime factor of (i.e.  ). Obviously, will be smoother than , but their smoothnesses might be of equal magnitude.
). Obviously, will be smoother than , but their smoothnesses might be of equal magnitude.
The difference between (in Pollard’s Method) and (in trial division) can be explained in terms of Lagrange’s Theorem. Moving from to  , we move from a group of order to one of order . Since a lot of the variety in AGLFAs comes from choosing groups with different orders, expect more of this in the following sections.
, we move from a group of order to one of order . Since a lot of the variety in AGLFAs comes from choosing groups with different orders, expect more of this in the following sections.
— 3. WILLIAMS’ METHOD —
Williams’ Method was first presented in a paper by Williams in 1982. This special-purpose factoring algorithm is directly inspired by Pollard’s Method (the prototypical AGLFA) and, as the name suggests, works best when has a prime factor for which is smooth.
The underlying group in Williams’ Method is the multiplicative group of the quadratic ring extension
![\displaystyle (\mathbb{Z}/N\mathbb{Z})[\sqrt{t}] = \{a+b\sqrt{t} : a,b \in \mathbb{Z}/N\mathbb{Z}\},](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%28%5Cmathbb%7BZ%7D%2FN%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D+%3D+%5C%7Ba%2Bb%5Csqrt%7Bt%7D+%3A+a%2Cb+%5Cin+%5Cmathbb%7BZ%7D%2FN%5Cmathbb%7BZ%7D%5C%7D%2C&bg=ffffff&fg=444444&s=0&c=20201002)
in which  is a quadratic non-residue mod . If
is a quadratic non-residue mod . If  , the Chinese Remainder Theorem implies that
, the Chinese Remainder Theorem implies that ![(\mathbb{Z}/N\mathbb{Z})[\sqrt{t}] \cong (\mathbb{Z}/p\mathbb{Z})[\sqrt{t}] \times (\mathbb{Z}/q\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=%28%5Cmathbb%7BZ%7D%2FN%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D+%5Ccong+%28%5Cmathbb%7BZ%7D%2Fp%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D+%5Ctimes+%28%5Cmathbb%7BZ%7D%2Fq%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) , which also extends to their unit groups.
, which also extends to their unit groups.
When 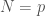 is prime, every element of
is prime, every element of ![(\mathbb{Z}/p\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=%28%5Cmathbb%7BZ%7D%2Fp%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) has a multiplicative inverse. To be specific,
has a multiplicative inverse. To be specific,

in which the denominators represent multiplication by  . (If this last inverse fails to exist,
. (If this last inverse fails to exist,  , which implies
, which implies 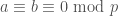 since was chosen to be a quadratic non-residue.) Note that this implies that
since was chosen to be a quadratic non-residue.) Note that this implies that  by Lagrange’s Theorem.
by Lagrange’s Theorem.
If we adopted Pollard’s Method wholesale, we’d now attempt to find a unit 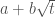 and an integer for which
and an integer for which
![\displaystyle \mathrm{ord}_p(a+b\sqrt{t}) \mid L \text{ in } (\mathbb{Z}/p\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7Bord%7D_p%28a%2Bb%5Csqrt%7Bt%7D%29+%5Cmid+L+%5Ctext%7B+in+%7D+%28%5Cmathbb%7BZ%7D%2Fp%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![\text{but for which} \qquad \mathrm{ord}_q(a+b\sqrt{t}) \nmid L \text{ in } (\mathbb{Z}/q\mathbb{Z})[\sqrt{t}].](https://s0.wp.com/latex.php?latex=%5Ctext%7Bbut+for+which%7D+%5Cqquad+%5Cmathrm%7Bord%7D_q%28a%2Bb%5Csqrt%7Bt%7D%29+%5Cnmid+L+%5Ctext%7B+in+%7D+%28%5Cmathbb%7BZ%7D%2Fq%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D.&bg=ffffff&fg=444444&s=0&c=20201002)
Unfortunately, it’s not so easy, and we’re not quite done. Since the multiplicative group of a field is cyclic, it’s certainly possible (and not at all unlikely, even) that 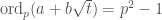 . In this case, searching for a candidate in the sequence would require to be at least as large as the largest prime factor of
. In this case, searching for a candidate in the sequence would require to be at least as large as the largest prime factor of 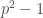 . Since
. Since  , we’re impeded by large factors of and of , which makes our current approach no better than Pollard’s Method.
, we’re impeded by large factors of and of , which makes our current approach no better than Pollard’s Method.
In theory, fixing this is simple: we just consider  instead. But, lest we forget, we don’t know the value of ahead of time. And yet, somehow, this doesn’t stop us. To see why, consider
instead. But, lest we forget, we don’t know the value of ahead of time. And yet, somehow, this doesn’t stop us. To see why, consider


in which we’ve used the binomial theorem, the fact that 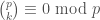 unless
unless 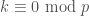 , Euler’s Criterion, Fermat’s Little Theorem, and the fact that is a quadratic non-residue. It follows that
, Euler’s Criterion, Fermat’s Little Theorem, and the fact that is a quadratic non-residue. It follows that

This formula still refers to , but we can make the visible -dependence go away by computing the right-hand side as an element ![A+B\sqrt{t} \in (\mathbb{Z}/N\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=A%2BB%5Csqrt%7Bt%7D+%5Cin+%28%5Cmathbb%7BZ%7D%2FN%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) . Now, we attempt to find an for which
. Now, we attempt to find an for which
![\displaystyle \mathrm{ord}_p(A+B\sqrt{t}) \mid L \text{ in } (\mathbb{Z}/p\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7Bord%7D_p%28A%2BB%5Csqrt%7Bt%7D%29+%5Cmid+L+%5Ctext%7B+in+%7D+%28%5Cmathbb%7BZ%7D%2Fp%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![\displaystyle \text{but for which} \qquad \mathrm{ord}_q(A+B\sqrt{t}) \nmid L \text{ in } (\mathbb{Z}/q\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7Bbut+for+which%7D+%5Cqquad+%5Cmathrm%7Bord%7D_q%28A%2BB%5Csqrt%7Bt%7D%29+%5Cnmid+L+%5Ctext%7B+in+%7D+%28%5Cmathbb%7BZ%7D%2Fq%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) .
.
By construction,  is a divisor of . Moreover, we expect
is a divisor of . Moreover, we expect  once gets as large as the largest prime factor of . But once this occurs, we can detect it by computing a certain GCD. This comes together as Williams’ algorithm:
once gets as large as the largest prime factor of . But once this occurs, we can detect it by computing a certain GCD. This comes together as Williams’ algorithm:
- Choose some
 which is a quadratic non-residue mod all primes
which is a quadratic non-residue mod all primes  .
.
- Choose a random/convenient value
![a+b\sqrt{t} \in (\mathbb{Z}/N\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=a%2Bb%5Csqrt%7Bt%7D+%5Cin+%28%5Cmathbb%7BZ%7D%2FN%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) and compute
and compute

- Starting at , replace
 with
with  .
.
- Compute
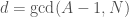 or
or  .
.
- If , return , a non-trivial factor of (and stop).
- If , return to Step 1 and choose a new and .
- Increment and return to Step 3.
As you might guess, the typical runtime of Williams’ Method is , in which is the largest prime factor of . There are plenty of cases, for example

in which the Williams’ Method outperforms both trial division and Pollard’s Method. Still, we mustn’t forget that Williams’ Method is a special-purpose factoring algorithm, which is typically no faster than trial division.
Remark — There is no known algorithm to deterministically perform Step 1 without essentially factoring along the way. In practice, one chooses at random and hopes that it was a quadratic non-residue mod the prime for which is smoothest. This will happen about 50% of the time, so it’s a good idea to run Williams’ algorithm more than once if it fails the first time. It’s also worth noting that Williams’ Method degenerates into a less efficient version of Pollard’s Method when is a quadratic residue, which is not ideal but also not the worst outcome.
There’s nothing stopping a program like Mathematica from incorporating Williams’ Method into their factoring suite. That being said, I’ve never seen it put to the test in a serious context. It may be that the Williams’ Method fails too often to bother implementing. (See here for further comparison to Pollard’s Method.)
— 4. FACTORING WITH CYCLOTOMIC POLYNOMIALS —
The which appears in Williams’ Method arises from the computation  . If we replace the quadratic extension
. If we replace the quadratic extension ![(\mathbb{Z}/N\mathbb{Z})[\sqrt{t}]](https://s0.wp.com/latex.php?latex=%28%5Cmathbb%7BZ%7D%2FN%5Cmathbb%7BZ%7D%29%5B%5Csqrt%7Bt%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) with an extension of degree , we’d produce a factoring method which relied on the smoothness of
with an extension of degree , we’d produce a factoring method which relied on the smoothness of  . With a bit of care, we can eliminate some of the factors of and require only that
. With a bit of care, we can eliminate some of the factors of and require only that 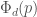 be smooth, where
be smooth, where 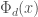 is the -th cyclotomic polynomial. This completely subsumes the algorithms due to Pollard and Williams, since
is the -th cyclotomic polynomial. This completely subsumes the algorithms due to Pollard and Williams, since  and
and  .
.
This technique was first published in 1989 by Bach and Shallit. Unfortunately, it remains mostly a curiosity, since is far less likely to be smooth as increases in size. The degree of is 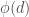 , which is at least two for
, which is at least two for 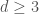 . Since the likelihood that
. Since the likelihood that  is smooth decreases as
is smooth decreases as  , the odds of success with a larger cyclotomic polynomial are negligible. This is a common problem with AGLFAs, one which really restricts the viability of algorithms in this class.
, the odds of success with a larger cyclotomic polynomial are negligible. This is a common problem with AGLFAs, one which really restricts the viability of algorithms in this class.
— 5. LENSTRA’S ELLIPTIC CURVE METHOD —
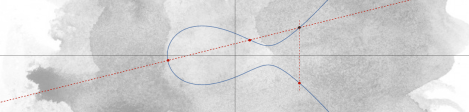
The elliptic curve method (ECM) was first presented in a paper by Lenstra in 1987. Like Williams’ Method, the ECM was directly inspired by Pollard’s Method. Here, the group of integers is replaced by the group of points on an elliptic curve.
More specifically, one picks a random elliptic curve  over and a non-identity point
over and a non-identity point  on
on 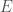 . Using the addition law on elliptic curves, we compute
. Using the addition law on elliptic curves, we compute  for in the sequence . By the Chinese Remainder Theorem, this addition can be viewed mod , for each prime . If ever
for in the sequence . By the Chinese Remainder Theorem, this addition can be viewed mod , for each prime . If ever 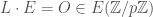 , the
, the  -coordinate of will be divisible by . But this can be detected with a GCD computation, which gives us a method for factoring .
-coordinate of will be divisible by . But this can be detected with a GCD computation, which gives us a method for factoring .
If we restrict to a single curve , this algorithm functions exactly like Pollard’s Method, except with replaced by the order of the group  . By Hasse’s Theorem,
. By Hasse’s Theorem,  , in which
, in which  depends on and satisfies
depends on and satisfies 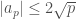 . If we’re lucky and
. If we’re lucky and 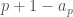 is particularly smooth, we’ll factor in short order.
is particularly smooth, we’ll factor in short order.
More likely, will not cooperate. But here lies the advantage of the ECM over Pollard’s Method: we can throw out and repeat our process with a new elliptic curve. Under the Sato–Tate Conjecture, varies in the interval ![[-2\sqrt{p},2\sqrt{p}]](https://s0.wp.com/latex.php?latex=%5B-2%5Csqrt%7Bp%7D%2C2%5Csqrt%7Bp%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) according to a well-defined distribution. In particular, by trying many elliptic curves, we expect to find one for which is sufficiently smooth in a predictable amount of time.
according to a well-defined distribution. In particular, by trying many elliptic curves, we expect to find one for which is sufficiently smooth in a predictable amount of time.
By optimizing our definition of sufficiently smooth (and applying some heuristics for the number of smooth numbers in an interval), we obtain an algorithm which is sub-exponential in the smallest factor of . For this reason, the ECM is most commonly used to identify factors of moderate size (i.e. fifty-ish digits) in enormous composites. The largest factor found to date with ECM is an 83-digit divisor of 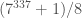 , found by Propper in 2013. (The leftovers form a 202-digit composite.)
, found by Propper in 2013. (The leftovers form a 202-digit composite.)
The generalization from elliptic curves to curves of higher genus is easy to do, but in the end, seems to be unhelpful. The reason for this is the same reason that factoring with cyclotomic polynomials is impractical: the odds of finding group with sufficiently smooth order decreases dramatically as the order increases in size.

Trial Division / Look-up Tables
SQUFOF / Pollard’s
Elliptic Curve Method (ECM)
Quadratic Sieve
General Number Field Sieve (GNFS)
